Gfi System, la empresa responsable de pedales como el Specular Reverb o el multiefectos de modulación Wavelogic ha presentado un nuevo dispositivo: se trata del simulador de altavoces de guitarra estéreo CabZeus.
El nuevo aparato viene a ser el sucesor de su anterior simulador ya descatalogado, y mucho más simple, el CabZilla. En esta ocasión, la empresa ha optado por un sistema digital de emulación mucho más detallado, que permite disponer de dos emulaciones de pantalla y/o micrófonos simultáneos
para poder enviar por separado en estéreo, o bien para ser mezclados.
Aunque el aparato no presenta muchos potenciómetros físicos, los ajustes
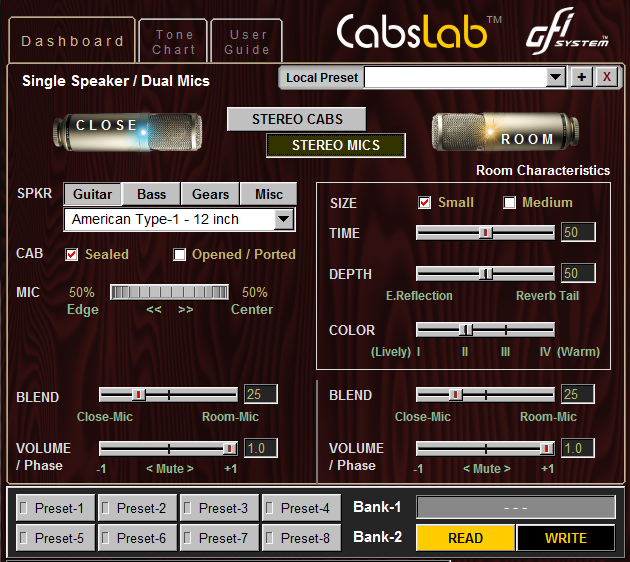
pueden realizarse mediante el software dedicado, llamado CabLabs. Se conecta con nuestro ordenador vía USB y que posibilita definir parámetros como: la ubicación del micrófono, su distancia, el tipo de altavoz o altavoces y su recinto, o configurar el tipo de coloración que aporta la habitación, así como su tamaño. Una vez ajustados, podemos almacenar diversas memorias con nuestros sonidos, de los que podremos disponer más tarde sin necesidad del ordenador.
El modo Stereo Mic permite usar una única pantalla y obtener dos señales separadas de dos micrófonos captándola
El modo Stereo Cab permite tener dos pantallas independientes cada una con su propio micro
En el apartado de entradas y salidas tenemos mucho donde elegir, ya que presenta entradas Estéreo (ideal para aquellos que utilicen sus delays o modulaciones también en Estéreo), cada una con su salida Thru independiente,
pudiendo obtener una señal sin emulación de pantalla de cada canal
(útil para enviarlo directo a una etapa de potencia o amplificador
mientras enviamos la señal emulada por PA). Por supuesto, tiene dos salidas L y R que llevan el efecto de emulación, y que pueden funcionar de forma balanceada o sin balancear (dependiendo de si usamos cable Mono o Estéreo). También viene con una salida de auriculares con su propio volumen dedicado, para poder practicar de forma silenciosa, y una entrada MIDI,
que le permite recibir órdenes de nuestra pedalera controladora y así
coordinar cada preset con nuestros sonidos. El CabZeus estará disponible
a partir del 21 de Noviembre.
La adición más reciente a la familia de pedales de la empresa KHDK Electronics, dirigida por el guitarrista de Metallica, Kirk Hammett y el gurú de los pedales David Karon, es el nuevo Dark Blood Overdrive. Se trata de una nueva unidad que apunta a las distorsiones más intensas.
El Dark Blood Overdrive se basa en tecnología de estado sólido y
mosfet, y lleva un booster de agudos en el principio del circuito, para
obtener una respuesta más cercana a los géneros del Metal. Según la
marca, el tipo de saturación que ofrece es similar a la que se podría
obtener de un amplificador. En cuanto a sus controles, encontramos los
clásicos Gain, Volume y Tone, pero también un control llamado “Doom”.
Según la explicación de la página web del producto, controla el nivel
de saturación en frecuencias graves previo al circuito de distorsión,
para hacer más fácil obtener sonidos más solistas o rítmicos debido a la
rapidez de la respuesta en graves. Además, incorpora dos selectores,
que nos permiten activar o desactivar la puerta de ruido y elegir entre los modos de alta y baja ganancia.
Además, Kirk Hammett promociona su propio producto añadiendo que ha
sido usado para la grabación de su propio disco, que sale a la venta
este viernes. “Este es el pedal definitivo para los fanáticos de la
ganancia. Me conecté a él y el nombre Dark Blood vino a mi mente. En ese
momento, sabía que este pedal iba a estar en el nuevo álbum”. Para
todos aquellos seguidores del guitarrista que además les guste
coleccionar sus artículos, habrá una edición limitada a 100 unidades con
la firma de Hammett y en acabado anodizado.
¿Qué sucede realmente con el volumen de una
señal de audio cuando se comprime? En el presente artículo vamos a
explicar porqué cuando se comprime una señal de audio se tiene la
sensación de que se ha elevado su volumen.
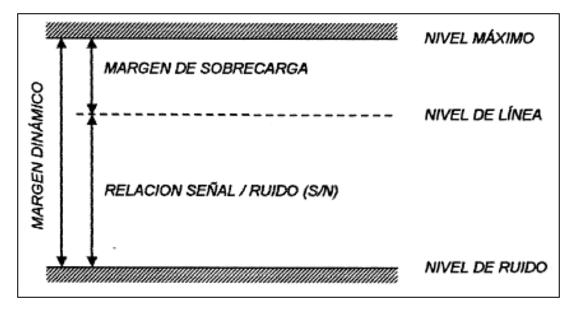
Lo primero que se ha de considerar es la diferencia entre el margen dinámico de la señal y el volumen de esta.
El margen dinámico establece la distancia entre el nivel máximo de
señal y el nivel mínimo o ruido que encontramos en cualquier señal de
audio. El volumen está relacionado con el nivel medio de la señal, el
valor RMS, que viene determinado por el nivel de la señal, el contenido
en frecuencia y la duración de esta.
Existen diferentes tipos de compresores: lineal, de ganancia constante, bilineal, multibanda... Vamos a centrarnos en el funcionamiento de los dos primeros.
Compresor lineal
Si atendemos a la definición de la función que realiza un compresor lineal, esta nos dice que aplicará amplificación
sobre las señales de entrada que se encuentren con un valor por debajo
de un valor determinado denominado umbral (threshold), y aplicará atenuación
sobre señales de entrada que se encuentren por encima de dicho valor
umbral. Es fácil interpretar que los niveles máximo y mínimo de señal
estarán más cerca tras el proceso de compresión, por lo tanto se reduce el margen dinámico en una proporción igual a la relación de compresión (también conocida como ratio).
Entonces, si la dinámica es menor... ¿por qué suena más alto? La
respuesta es simple: cuando queremos elevar el volumen de una señal,
estamos condicionados por sus picos; de ese modo, para que la señal no
sature, apuramos hasta el nivel máximo del margen dinámico, ocupando
incluso el valor de sobrecarga, y ajustamos el valor medio final de la
señal en función de esos transitorios de señal que nos marcan el valor
máximo de la misma.
Sound Advice on Compressors, Limiters, Expanders and Gates, Bill Gibson, Ed. ProAudio Press.
Al aplicar una compresión lineal, la dinámica se reduce, y también lo
hace en la misma proporción la distancia entre el valor máximo de señal
marcado por esos valores transitorios y el valor medio de programa. Es
en este momento cuando podemos elevar toda la señal de audio, volviendo a
ajustar el valor máximo de señal al techo dinámico del sistema, y
estaremos aplicando también una elevación del nivel medio del programa, es decir, del volumen, que ahora al estar más cerca del techo dinámico, tiene un valor más alto.
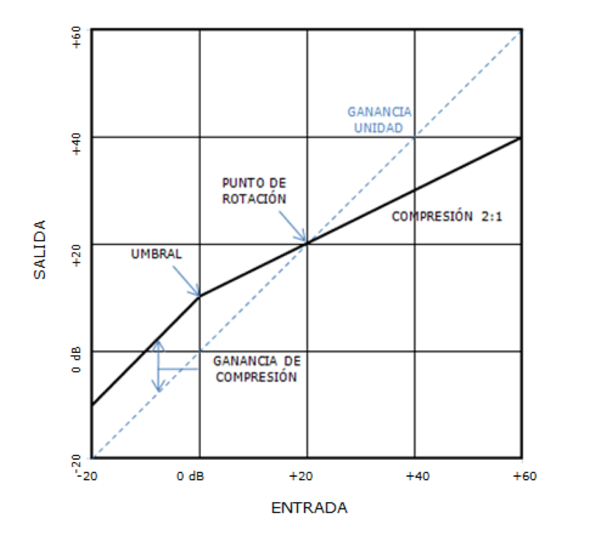
Compresor de ganancia constante
Con este otro tipo de compresor, el procesado sobre la dinámica de la
señal de sonido es algo diferente. Estos compresores tienen dos zonas
de actuación bien diferenciadas:
La primera de ellas es la que procesa las señales con nivel de
entrada inferior al valor umbral, a las que se le aplica una
amplificación de igual valor para todas ellas, denominada ganancia de
compresión.
La segunda es la que procesa las señales con nivel de entrada
superior al valor umbral, aplicándoles la relación de compresión
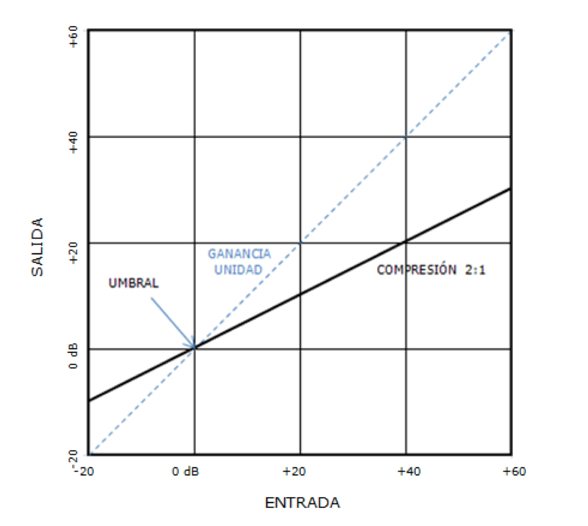
establecida. En esta zona encontramos el punto de rotación, que es el
valor para el cual el compresor presenta ganancia unidad, es decir, la
recta que determina la relación de compresión se cruza aquí con la recta
que representa la ganancia unidad del sistema. En esta zona el
compresor aplicará amplificación sobre los valores que estén por debajo
del punto de rotación (recordemos que están por encima del umbral) y
atenuación sobre los valores que estén por encima del punto de
rotación.
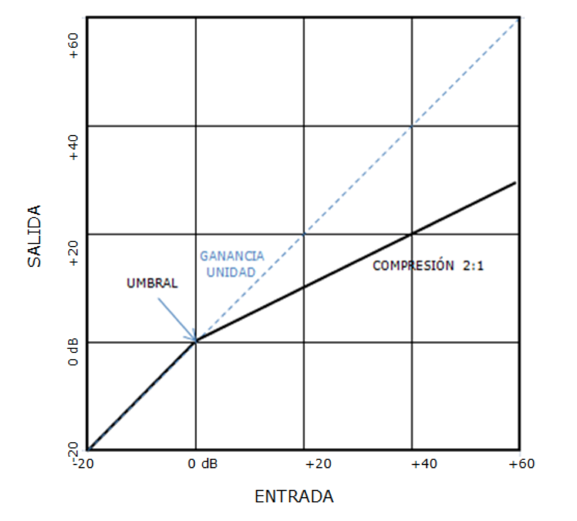
Resulta un caso muy habitual el mostrado en la siguiente figura, en
la que el valor de ganancia de compresión es 0 dB, haciendo coincidir
esta zona con la recta de ganancia unidad del sistema.
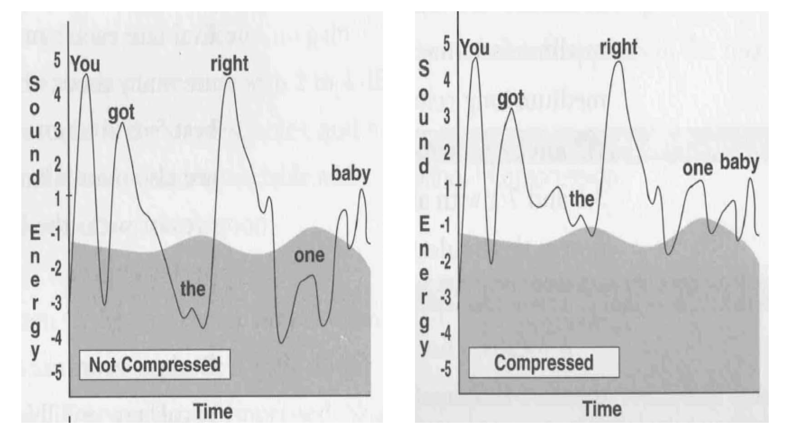
De este modo sólo se procesa, se comprime (reduciendo la dinámica) la
señal de audio que se encuentra por encima del valor umbral,
reduciéndose la dinámica en la parte regulada por los picos, por las
zonas de alto nivel de señal, que no nos dejaban elevar el nivel medio
de programa, ya que estos picos estaban ocupando la zona de sobrecarga
del sistema. Una vez que se han reducido los transitorios ya es posible
elevar de forma efectiva el nivel medio de programa, tal y como puede
verse en la figura.
Sound Advice on Compressors, Limiters, Expanders and Gates, Bill Gibson, Ed. ProAudio Press.
En los dos casos vistos del compresor de ganancia constante se reduce
la distancia en dinámica existente desde el valor más elevado de la
señal de audio (valor de pico) al valor medio (valor RMS) de la misma,
lo que permite que podamos ajustar la señal al techo dinámico del
sistema elevando el valor medio de programa, lo que hace que escuchemos
la señal con un volumen mayor.
Si nos detenemos a analizar las posibilidades de edición de audio, en
muchos sentidos ya contamos con herramientas equivalentes a lo que
sería Photoshop para fotografías pero en términos de audio, pudiendo
retocar, modificar, combinar, filtrar y procesar de muchas maneras el
material de audio. Sin embargo, aún queda un largo trecho cuando se
trata de procesos de resíntesis de material que sean suficientemente
fieles a las muestras crudas.
En su reciente conferencia MAX, la gente de Adobe, responsable de
piezas populares de software como Photoshop, Illustrator y Audition, ha presentado
lo que consideran un “photoshop para audio”, al menos en términos de la
grabación de voces, como comentó el desarrollador Zeyu Jin en la
presentación del llamado proyecto VoCo, un algoritmo que, sin afirmar si llegará a estar disponible comercialmente, presentó con algunos ejemplos interesantes.
Se trata de un agregado de Adobe Audition desarrollado por miembros
del equipo de investigación de la compañía y la Universidad de
Princeton. El software se basa en un sistema de resíntesis que permite editar y agregar palabras a un determinado discurso, pudiendo (re)sintetizar la voz registrada.
En la presentación por ejemplo, se puede apreciar como en una frase
donde dice “besó a sus perros y su mujer” intercambia los sustantivos
desde texto, luego agrega la palabra “jordan” en vez de “mujer” y
posteriormente agrega material que no incluye la grabación, “tres
veces”.
Aunque en el comunicado oficial de Adobe se habla de la posibilidad de “cambiar o insertar una o varias palabras en grabaciones de doblaje, diálogo y narración” debido
a errores o cambios necesarios, es claro que una tecnología de estas
puede tener muchos usos, algunos de ellos quizás no muy benéficos cuando
se trata de asuntos políticos, material de evidencia, entre otros, para
los cuales no es de extrañar que ya existan tecnologías similares. De
hecho en su presentación se menciona que ha sido más fácil lograr el
algoritmo que hacer que el sistema tenga una especie de función de marca
de agua de tal forma que se detecte cuando fue hecho así, en caso de
que pueda caer en manos equivocadas.
Sin embargo, más allá de nuestras conspiraciones y los interrogantes
éticos que de un software así puedan desprenderse, es importante
destacar lo mucho que se acerca el algoritmo a la síntesis de una voz
tan similar a la identificada en el discurso. Para ello, según comentan
los de Adobe, es necesario tener al menos 20 minutos de grabación de una voz, de tal forma que se pueda analizar el material lo suficiente como para recrearla en otras palabras.
Como el mismo Zeyu Jin comentó en la conferencia, su idea es generar
en el audio una revolución similar a la que causaron con Photoshop en
términos de la fotografía. No se sabe si VoCo es apenas el comienzo de
otras herramientas similares, pero es claro que tienen al menos algo de
interés en el audio, por lo que será cuestión de tiempo conocer lo que
se traen entre manos. Por lo pronto, no se tiene más información sobre
VoCo.
IK Multimedia fue de las primeras empresas en
apostar fuertemente por las posibilidades del iPhone como plataforma
válida para ser utilizada con nuestra guitarra. Su iRig tuvo una buena
aceptación y, junto a otros productos, supuso la punta de lanza de un
nuevo sector de productos, el de las interfaces de guitarra para
dispositivos móviles. Tras varias versiones del iRig, en esta ocasión
presentan el nuevo iRig HD 2, del que sus fabricantes informan estar con el nuevo iPhone 7 en mente (aunque aparentemente no se ha dicho que haya restricciones de compatibilidad con otros dispositivos).
Por supuesto el nuevo iRig mantiene sus
funciones principales: nos permite conectar nuestra guitarra mediante un
jack convencional y enviar su señal (cuyo nivel es ahora regulable) a
nuestro iPhone o dispositivo móvil, desde donde podemos procesarla. Los
iRig acostumbran a funcionar con diversas aplicaciones que tengamos
instaladas, pero lo cierto es que están especialmente pensados para el
software propia de la marca, el IK Multimedia Amplitube, peropor
suerte, parece ser que los compradores de esta interfaz tendrán derecha
a la descarga gratuita de la versión completa. Tras el procesamiento
mediante software, la señal se reproduce a través de las dos salidas que
ofrece esta versión: la de amplificador y la de auriculares.
La salida de amplificador es una conexión en formato jack, para evitar el uso de adaptadores y que tiene dos modos de funcionamiento, FX y Thru. El primero envía nuestro sonido con todo el procesamiento del software, mientras que el segundo hace un bypass completo y envía nuestra señal seca, algo que puede ser útil para contextos de grabación.
En cuanto a la salida de auriculares, dispone de un volumen propio
integrado en la interfaz, que podemos regular físicamente. Si sois
seguidores de Apple, seguro habréis leído que el nuevo iPhone carece de salida de auriculares propia.
En efecto, aunque cueste de creer, el nuevo iPhone sólo trabaja
mediante su conector lightning o mediante dispositivos inalámbricos.
Dicho esto, IK Multimedia hace notar que una
de las prestaciones que ofrece el iRig al conectarse al iPhone via
lightning es la de recuperar la prestación del conector minijack
convencional.
El iRig HD 2 viene con un adaptador especial para su fijación a un pie
de micro y velcro para poder ser fijado a superficies planas. El precio
de esta interfaz está entorno a 122 euros, pero por el momento sólo es posible reservarlo hasta su fecha de lanzamiento, prevista para finales de este mes.